Двенадцать ИИ-агентов. Одна кодовая база. Сорок семь часов. 737 закрытых тикетов, 826 коммитов. Всё, что могло сломаться, сломалось. Оркестратор, который я написал, чтобы можно было поспать, теперь в open source.

Потолок одного агента
Обещание ИИ-ассистентов для кода звучит просто. Промпт, код, ревью, готово. На практике потолок ниже, чем в демо.
Нянчишь одного агента, одно контекстное окно, одну задачу. Через час модель плывёт. Галлюцинирует сигнатуры. Забывает ограничения. Объясняешь заново. Плывёт опять. Девять других задач стоят.
Дальше - привязка. Каждый multi-agent фреймворк, что я пробовал (CrewAI, Microsoft Agent Framework, бывший AG2, LangGraph), привязывает оркестрацию к одному API провайдера. Дешёвая модель на boilerplate и сильная на архитектуру в одном запуске? Не выйдет.
Разрыв между «ИИ пишет код» и «ИИ шипает протестированный код с чистой git-историей» - это та часть, которую не показывают в демо.
Что реально сломалось
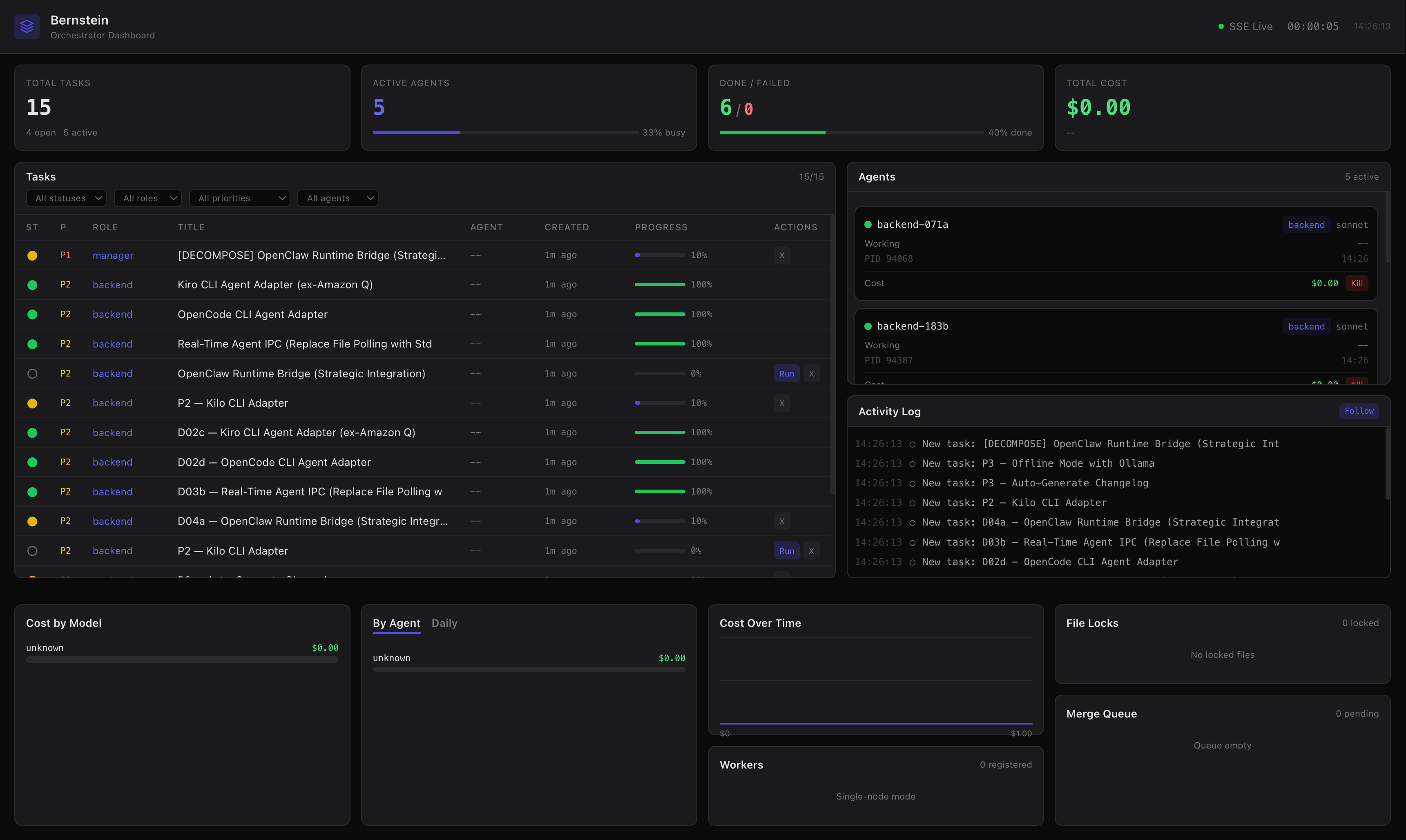
Направил 12 агентов на реальный backlog, чтобы посмотреть, что будет.
Что сломалось. Merge conflicts от двух агентов, редактирующих один файл. Port collisions от одновременных dev-серверов. Один агент сжёг $40 в цикле повторов. Агенты затирали работу друг друга, потому что не было файловых блокировок. Долгоживущие агенты плыли, пока их код не начинал противоречить их же собственному раннему коду. Где-то на тридцатом часу я поймал 30 orphan claude процессов за один час. Реальный балаган.
Каждое архитектурное решение в Bernstein - прямой фикс чего-то, что сломалось в том запуске. Это шрамы, переписанные как README.
Одна команда
pipx install bernstein
bernstein -g "Add JWT auth with refresh tokens, tests, and API docs"Bernstein разбивает цель на задачи, назначает каждой агента с нужной моделью и ролью, запускает их в изолированных git worktree, проверяет, что тесты проходят, и коммитит выжившее. Возвращаешься к работающему коду или к отчёту, что сломалось.
Архитектура
Ближайшая аналогия - то, что Kubernetes сделал для контейнеров, но для CLI coding agents. Задаёшь цель. Control plane декомпозирует её в задачи. Короткоживущие агенты выполняют их в изолированных worktree как поды. Janitor проверяет результат до того, как что-то попадёт в код.
Оркестратор - детерминированный Python. Ноль токенов на координацию. Никакой LLM не решает, что делать дальше. Никакого недетерминизма в scheduling. Никакой рекурсии agent-manages-agents. Только начальная декомпозиция цели обращается к LLM. Дальше - код.
Короткоживущие агенты. Спавн, работа в минутах, выход. Нет context drift. Если задача упала, retry со свежим агентом. Старого уже нет.
File-based state. Всё живёт в .sdd/, обычные файлы в репозитории. Смотри, диффай, версионируй. Ничего не прячется в памяти.
Janitor. Каждый результат проверяется. Тесты пройдены, файлы на месте, регрессий нет. Агенты сами себя не сертифицируют.
Open API. Локальный HTTP-сервер на порту 8052. Любой CI pipeline, Slack-бот или cron job может создавать задачи. Bernstein встраивается в workflow. Не заставляет перестраиваться вокруг себя.
Любой агент, любая модель
Bernstein работает с любыми установленными CLI-агентами. Claude Code на архитектуру, Codex на тесты, Gemini на документацию, в одном запуске. Добавить нового агента - это 50 строк Python-адаптера.
| Bernstein | CrewAI | AG2 / Agent Framework1 | LangGraph | |
|---|---|---|---|---|
| Scheduling | Детерминированный код | LLM-based | LLM-based | Graph |
| Время жизни агента | Короткое (минуты) | Долгое | Долгое | Долгое |
| Верификация | Встроенный janitor | Вручную | Вручную | Вручную |
| CLI agents | Любые установленные | Только API | Только API | Только API |
| Model lock-in | Нет | Мягкий | Мягкий | Мягкий |
Когда Claude Code выпускает новую версию, улучшение приходит бесплатно. Появляется новый CLI agent, присоединяется к пулу. Оркестрационный слой не знает, какой агент делает работу.
Цифры
1.78x пропускная способность против single-agent baseline на том же наборе задач. Не маркетинговый 10x. Измеренный результат с overhead на координацию внутри.
23% ниже стоимость. Короткие контекстные окна тратят меньше input-токенов. Микширование моделей направляет дешёвые задачи на дешёвые модели.
4250+ тестов в самом репозитории Bernstein. Каждая задача, выполненная агентом, проходит верификацию по этому набору.
Budget caps. --budget 5.00 предупреждает на 80%, алертит на 95%, жёстко останавливает на 100%. Несущая инфраструктура, а не театр безопасности.
Self-evolution. bernstein --evolve анализирует метрики и предлагает изменения промптов и правил маршрутизации. Risk-gated. L0 применяется автоматически. L3 требует одобрения. Circuit breaker останавливает при регрессии тестов.
Три команды
pipx install bernstein
cd your-project && bernstein init
bernstein -g "Your goal here"Для CI есть GitHub Action:
- uses: chernistry/bernstein-action@v1
with:
goal: "Fix all failing tests and update snapshots"
budget: "5.00"Инструмент молодой, шероховатостей хватает. Если на что-то наткнулись, откройте issue. Интересная задача - заставить много агентов не наступать друг другу на ноги, а не сделать одного агента умнее.

Footnotes
-
AutoGen перешёл в режим поддержки и был заменён Microsoft Agent Framework (апрель 2026). ↩