Twelve AI coding agents. One codebase. Forty-seven hours. 737 tickets closed, 826 commits landed. Everything that could break, broke. The orchestrator I wrote so I could go to sleep is now open source.

The single-agent ceiling
The pitch for AI-assisted coding sounds simple. Prompt, code, review, done. In practice the ceiling is lower than the demo.
You babysit one agent, one context window, one task at a time. After an hour the model drifts. Hallucinated function signatures. Forgotten constraints. You re-explain. It drifts again. Meanwhile nine other tasks sit idle.
Then there is the lock-in. Every multi-agent framework I tried (CrewAI, Microsoft Agent Framework, ex-AG2, LangGraph) couples orchestration to one provider's API. Mix a cheap model for boilerplate with a strong one for architecture? Out of luck.
The gap between "AI writes code" and "AI ships tested code with a clean git history" is the part nobody demos.
What actually broke
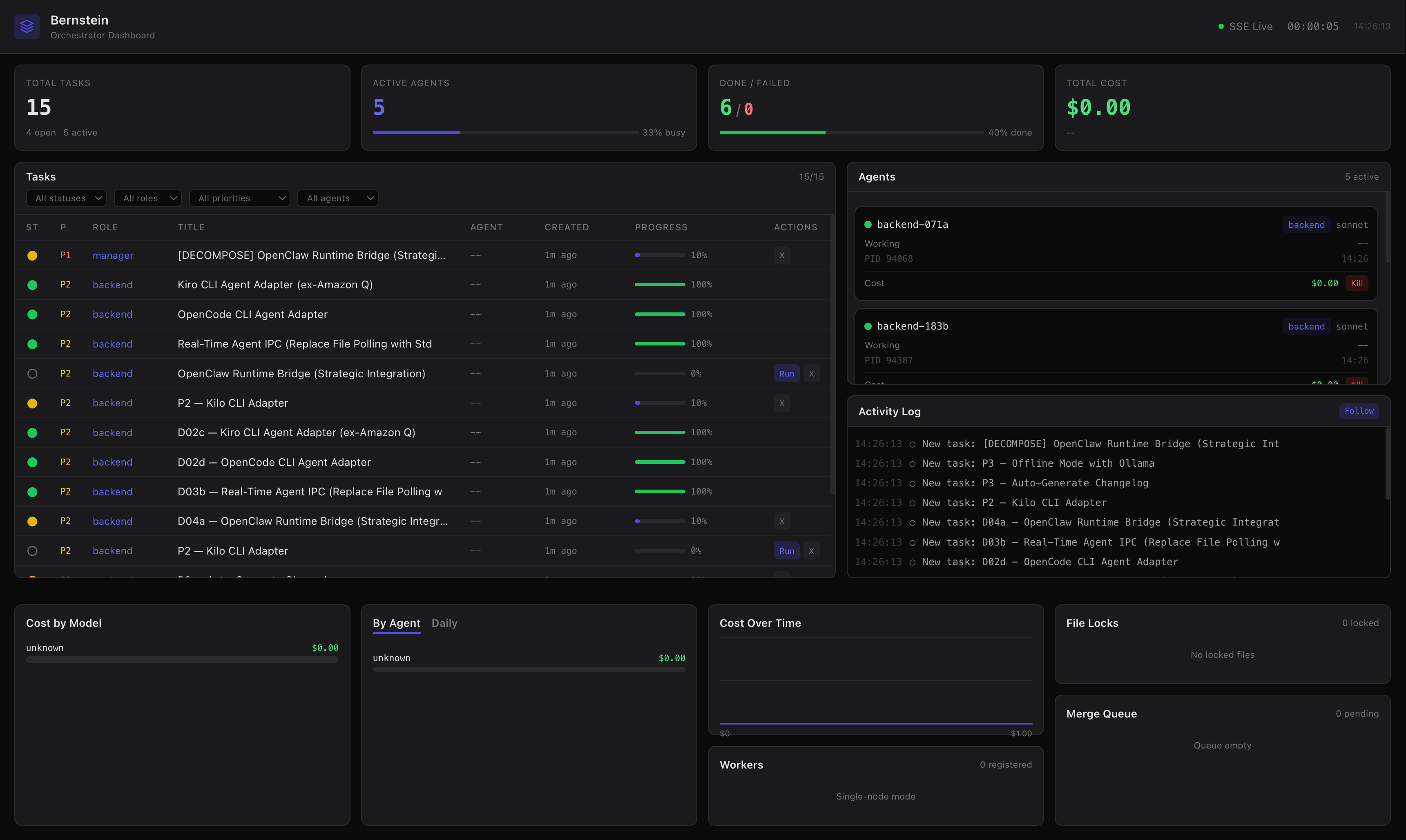
I pointed 12 agents at a real backlog to see what would happen.
What broke. Merge conflicts when two agents edited the same file. Port collisions from simultaneous dev servers. One agent burned $40 in a retry loop. Agents overwrote each other's work because there was no file locking. Long-running agents drifted until their output contradicted their own earlier code. Around hour 30 I logged 30 orphan claude processes in a single hour. Real balagan.
Every design decision in Bernstein is a direct fix for something that failed in that run. The list above is the scar-tissue version of the README.
One command
pipx install bernstein
bernstein -g "Add JWT auth with refresh tokens, tests, and API docs"Bernstein breaks the goal into tasks, assigns each to an agent with the right model and role, runs them in isolated git worktrees, verifies tests pass, and commits what survives. You come back to working code, or a clear report of what failed.
Architecture
Closest analogy is what Kubernetes did for containers, but for CLI coding agents. You declare a goal. The control plane decomposes it into tasks. Short-lived agents execute them in isolated worktrees like pods. A janitor verifies the output before anything lands.
The orchestrator is deterministic Python. Zero tokens on coordination. No LLM deciding what to do next. No nondeterminism in scheduling. No agent-managing-agents recursion. Only the initial goal decomposition touches an LLM. After that it is code.
Short-lived agents. Spawn, work for minutes, exit. No context drift. If a task fails, retry with a fresh agent. The old one is already gone.
File-based state. Everything lives in .sdd/, plain files in your repo. Inspect, diff, version. Nothing hides in memory.
Janitor. Every result gets verified. Tests pass, files exist, no regressions. Agents do not self-certify.
Open API. Local HTTP server on port 8052. Any CI pipeline, Slack bot, or cron job can create tasks. Bernstein fits your workflow. You do not rebuild around it.
Mix any agent, any model
Bernstein runs whatever CLI agents you have installed. Claude Code on architecture, Codex on tests, Gemini on docs, same run. Adding a new agent is a 50-line Python adapter.
| Bernstein | CrewAI | AG2 / Agent Framework1 | LangGraph | |
|---|---|---|---|---|
| Scheduling | Deterministic code | LLM-based | LLM-based | Graph |
| Agent lifetime | Short (minutes) | Long-running | Long-running | Long-running |
| Verification | Built-in janitor | Manual | Manual | Manual |
| CLI agents | Any installed | API-only | API-only | API-only |
| Model lock-in | None | Soft | Soft | Soft |
When Claude Code ships a better version, you get the improvement for free. When a new CLI agent appears, it joins the pool. The orchestration layer does not know which agent does the work.
Numbers
1.78x throughput vs. single-agent baseline on the same task set. Not a 10x marketing claim. A measured number, with coordination overhead included.
23% lower cost. Short context windows waste fewer input tokens. Model mixing routes cheap tasks to cheap models.
4,250+ tests in the Bernstein codebase itself. Every agent-completed task gets verified against the suite.
Budget caps. --budget 5.00 warns at 80%, alerts at 95%, hard-stops at 100%. Load-bearing infrastructure, not safety theatre.
Self-evolution. bernstein --evolve analyses performance metrics and proposes changes to prompts and routing rules. Risk-gated. L0 auto-applies. L3 requires approval. Circuit breaker halts on test regression.
Three commands
pipx install bernstein
cd your-project && bernstein init
bernstein -g "Your goal here"For CI, there is a GitHub Action:
- uses: sipyourdrink-ltd/bernstein@v3
with:
task: "Fix all failing tests and update snapshots"
budget: "5.00"The tool is early. Rough edges everywhere. If you hit one, open an issue. The interesting problem is keeping many agents from stepping on each other, not making one agent smarter.

Footnotes
-
AutoGen entered maintenance mode and was succeeded by Microsoft Agent Framework (April 2026). ↩